One big problem of simple sequence searching with tools like
blast with ChEMBL is the problem of the introduction of contextually incorrect target relationships due to matching of irrelevant domains. For example, imagine a protein,
X, that contains two domains of types
A and
B, and a second protein,
Y, which contains also two domain types,
B and
C. If the ligand is known to bind to domain type
A, there is no ligand-binding relationship between
X and
Y; however, if the ligand binds at domain type
B in
X, then there is a relevant relationship between
X and
Y. This may sound like an rare example, but it is surprisingly common (and extremely annoying), since the majority of eukaryotic proteins are multi-domain, and the presence of certain domains, such as an EGF-like domain (Pfam:
pf00009) can greatly complicate the analysis of sequence searches. What is really needed is a reliable mapping (or more generally a probabilistic score) of the ligand-binding domains within a particular protein.
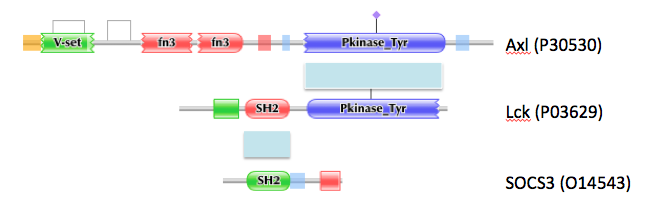
Enough of all these
Xs and
Ys! Here is a real example, for three interesting proteins,
Axl,
Lck and
SOCS3. As you can see, protein kinase domain inhibitors are only 'transferable' between Axl and Lck, while SH2 binders are only 'transferable' between Lck and SOCS3.
Here is a graph (as a pie chart) of the
Pfam domains for the ligand binding regions of all the protein targets in the current (Chembl_08) target dictionary. The annotation, was performed by a simple classifier heuristic, and we are validating the accuracy of this approach at the moment, but it appears to be largely correct. Once we're happy with the results, we'll add the ligand-binding-domain data to the target dictionary.


Comments